MCP 붙였다고 끝이 아닙니다: AI가 여전히 헤매는 진짜 이유
2026년 1월을 기점으로 커머스 운영 현장의 분위기가 눈에 띄게 바뀌었습니다. MCP(Model Context Protocol) 생태계가 다양한 플랫폼까지 확장되면서, 이를 연결하는 레퍼런스가 쏟아지기 시작했거든요

AI 시대의 커머스 브랜드에게 '데이터 관계'가 필요한 이유
2026년 1월을 기점으로 커머스 운영 현장의 분위기가 눈에 띄게 바뀌었습니다. MCP(Model Context Protocol) 생태계가 다양한 플랫폼까지 확장되면서, 이를 연결하는 레퍼런스가 쏟아지기 시작했거든요. 그동안 대행사에 맡기거나 운영자가 손으로 처리하던 반복 업무들이 하나둘 자동화되기 시작한 것도 이 시점부터입니다.
그런데 막상 본격적으로 써본 분들의 피드백은 대체로 이렇습니다.
"간단한 업무는 잘 돌아가는데, 진짜 필요한 분석은 여전히 AI가 헤매요."
특히 데이터 양이 적거나, 여러 형식으로 복잡하게 얽혀 있는 데이터일수록 Claude 같은 AI가 제대로 된 분석을 내놓지 못합니다. 이유는 분명합니다. MCP로 데이터를 불러오는 것까지는 쉬워졌지만, 그 데이터들이 서로 어떤 관계를 맺고 있는지는 MCP가 모르기 때문입니다.
물론 "이 데이터는 이런 의미고, 저 데이터와는 이렇게 연결된다"를 md 파일이나 지시서에 꼼꼼히 적어두면 어느 정도 보완할 수 있습니다. 하지만 여기에 더 큰 함정이 있습니다. 관계를 설명하려면 먼저 데이터의 본질을 이해하고 있어야 한다는 점이죠. 현장에서 데이터를 관리하는 담당자조차 "이 값이 정확히 뭘 의미하는지", "저 테이블이 다른 데이터와 어떻게 이어지는지" 모르는 경우가 허다합니다. 본질을 모르면 지시서를 쓸 수 없고, 지시서가 부실하면 AI 분석의 정밀도는 거기서부터 무너집니다.
결국 문제의 본질은 AI 성능이 아닙니다. AI에게 줄 데이터가, 서로 관계를 모른 채 흩어져 있다는 것. 2026년 현재 커머스 현장이 마주한 진짜 벽입니다.
커머스 데이터의 현실: 여섯 개의 섬

커머스 브랜드가 매일 쌓는 데이터는 생각보다 방대합니다. 크게 나누면 여섯 가지입니다.
-
주문 데이터 — Cafe24, 스마트스토어, 쿠팡에서 발생하는 매출·주문 내역
-
광고 데이터 — 메타, 구글, 네이버, 카카오에서 집행한 광고 성과
-
상품 데이터 — SKU, 카테고리, 가격, 재고
-
CS 데이터 — 카카오톡 채널, 채널톡, 콜센터로 들어온 문의·클레임
-
물류 데이터 — 출고, 배송, 반품, 교환 기록
-
고객 데이터 — 회원 정보, 구매 이력, 등급, 리뷰
문제는 이 데이터들이 각기 다른 시스템에, 다른 형식으로, 다른 사람이 관리한다는 점입니다. 광고는 마케팅팀이 대시보드로, CS는 CS팀이 엑셀로, 물류는 3PL 시스템이 따로, 주문은 쇼핑몰 솔루션에서 각각. 브랜드 하나가 6~10개의 '데이터 섬'을 운영하고 있는 셈이죠.
그리고 이 섬들은 서로 건너갈 다리가 없습니다.
섬 하나만 봐서는 아무것도 알 수 없다

파편화된 상태에서 "우리 브랜드 잘 되고 있나?"라는 질문에 제대로 답할 수 있을까요? 실제 현장에서 자주 벌어지는 일들을 보면 답이 나옵니다.
사례 1. ROAS 500% 캠페인인데 남는 게 없다
마케팅팀은 "A 캠페인 ROAS 500% 나왔어요!"라고 보고합니다. 그런데 몇 달 뒤 재무팀이 돌려보니 수익이 나지 않았습니다. 왜일까요?
그 캠페인으로 유입된 고객들의 반품률이 유독 높았고, CS 응대 시간도 평균의 2배였습니다. 광고 데이터만 봐서는 이걸 알 수가 없습니다. 광고·물류·CS 데이터가 하나의 고객 단위로 묶여 있어야 비로소 보이는 진실입니다.
사례 2. 베스트셀러인 줄 알았는데 손해 상품
상품 B는 주문 데이터상 월 매출 1위입니다. 그런데 광고비, 반품 비용, CS 응대 시간을 전부 반영해보면 실제 마진은 하위권이었습니다. 주문 데이터 하나만 보고 광고를 더 태웠다가 적자가 나는 경우가 실제로 많습니다.
"잘 팔린다"와 "돈이 된다"는 다른 이야기인데, 데이터가 섬으로 흩어져 있으면 이 차이를 볼 수 없습니다.
사례 3. "왜 이탈했는지 모르겠어요"
VIP 고객이 6개월째 구매가 없습니다. 주문 데이터만 봐서는 "그냥 이탈했다" 이상은 알 수 없습니다.
하지만 데이터를 연결해보면 이런 스토리가 나옵니다.
3개월 전 배송 지연 클레임 → 물류 기록상 실제 5일 늦게 도착 → CS 응대 완료되었으나 고객 재방문 없음 → 경쟁 브랜드 광고 클릭 이력 → 이탈
'왜'를 알아야 붙잡을 수 있는데, 데이터가 연결되지 않으면 '왜'가 영원히 보이지 않습니다.
AI 시대에 '데이터 관계'가 더 중요해진 이유
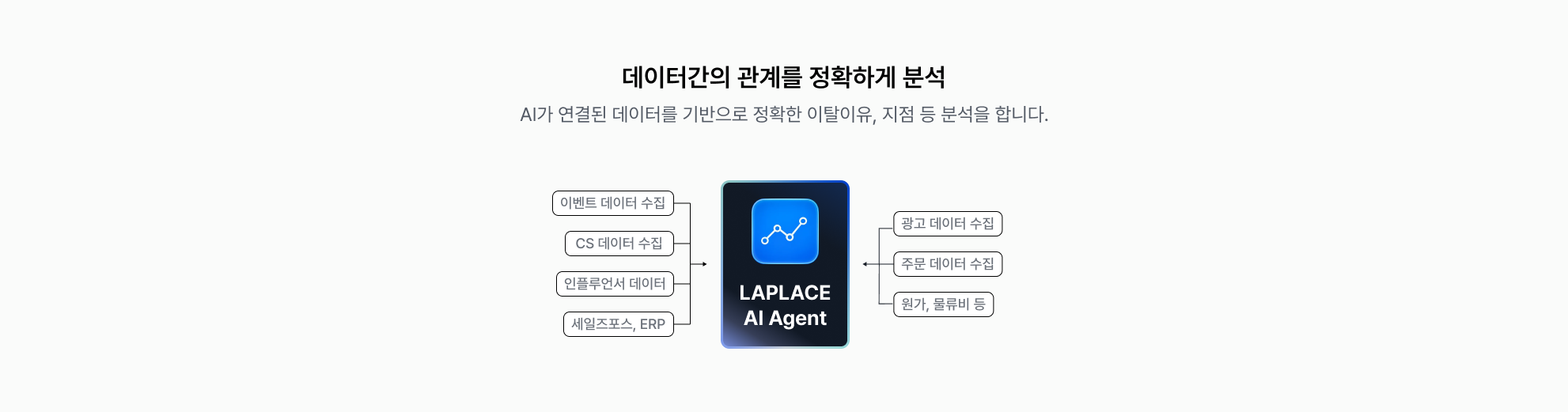
여기서 AI 이야기를 해봅시다. AI는 본질적으로 주어진 데이터 안에서만 추론합니다. 광고 엑셀 하나만 주면 광고 이야기만, 주문 CSV만 주면 매출 추이까지만 말할 수 있습니다.
"이 고객이 왜 이탈했을까?"처럼 여러 데이터를 가로지르는 질문에는, 여러 데이터를 가로지르는 맥락(context) 이 있어야 제대로 답합니다. 이 맥락을 만드는 것이 바로 '데이터 관계 설정' 입니다.
-
주문의 '고객 ID'와 CS의 '문의자 정보'가 연결되어야 → "이 주문이 CS 문의로 이어졌다"를 알 수 있음
-
광고의 '캠페인'과 주문의 '유입 경로'가 연결되어야 → "이 광고가 실제 매출을 만들었는지"를 알 수 있음
-
상품의 'SKU'와 물류의 '반품 기록'이 연결되어야 → "이 상품의 진짜 수익성"을 계산할 수 있음
관계가 없으면 데이터는 그냥 숫자 덩어리입니다. 관계가 설정되어야 비로소 의미가 생기고, AI는 의미 위에서 작동합니다.
뒤집어 말하면, 아무리 똑똑한 AI를 도입해도 데이터가 섬으로 남아 있는 한 AI는 섬 하나만 보고 답하게 됩니다. 이게 "답은 주는데 쓸 만하지 않다"의 정체입니다.
라플라스가 하는 일: '관계'를 인프라로 만드는 것
라플라스는 단순히 데이터를 한 곳에 모아주는 도구가 아닙니다. 흩어진 데이터 사이에 관계를 설정해주고, 그 관계를 AI가 이해할 수 있는 형태로 계속 유지·관리하는 인프라입니다.
구체적으로 라플라스가 커머스 브랜드를 위해 해결하는 것은 네 가지입니다.
- 서로 다른 플랫폼의 '같은 것'을 같은 것으로 묶기
Cafe24의 상품 코드 '001', 네이버의 'A123', 광고 데이터의 '프로모션 상품'이 사실 같은 SKU라는 걸 자동으로 인식합니다. 이게 안 되면 상품별 ROAS 같은 기본 지표조차 계산이 불가능합니다.
- 고객 한 명을 '한 명'으로 합치기
동일한 고객이 쇼핑몰에서 주문하고, 카카오톡으로 CS 문의하고, 채널톡으로 또 문의해도, 라플라스는 이를 한 명의 고객으로 통합합니다. 그래야 "이 고객의 전체 여정"이 보입니다.
- 시간 순서대로 관계 이어붙이기
"광고 클릭 → 상품 조회 → 구매 → 배송 → CS 문의 → 재구매 → 이탈"이라는 타임라인을 복원합니다. 각 단계가 다른 시스템에서 일어났더라도 하나의 고객 여정으로 연결됩니다.
- AI가 바로 쓸 수 있는 형태로 유지하기
데이터는 매일 변합니다. 신상품이 들어오고, 고객이 가입하고, 광고 캠페인이 바뀌죠. 관계를 한 번 설정하는 게 아니라 매일 유효하게 유지하는 것이 인프라가 하는 일입니다.
데이터 생태계가 완성되면 비로소 답할 수 있는 질문들
관계가 설정된 데이터 위에서는, 이전에는 물어볼 수조차 없던 질문에 답할 수 있습니다.
-
"지난달 신규 유입 고객 중, 어떤 채널에서 들어온 사람이 재구매까지 이어졌나?"
-
"반품률이 높은 상품과 낮은 상품의 CS 문의 패턴은 어떻게 다른가?"
-
"VIP 고객이 이탈하기 3개월 전에 어떤 신호가 있었나?"
-
"이 광고 캠페인이 데려온 고객들의 LTV는 얼마고, 실제 수익은 얼마인가?"
-
"재구매율이 유독 낮은 시기에 우리 브랜드에 무슨 일이 있었나?"
이런 질문은 엑셀로도, 단일 대시보드로도 답하기 어렵습니다. 하지만 데이터 관계가 설정된 인프라 위에서는 AI에게 자연어로 물어봐도 정확한 답이 돌아옵니다. 운영자가 '데이터 정리'가 아니라 '의사결정'에 시간을 쓸 수 있게 되는 지점이 바로 여기입니다.
마무리: "AI 도입"보다 먼저 해야 할 일
많은 브랜드가 "우리도 AI 도입해야지"라고 생각합니다. 하지만 뭔가 다될것 같은데 안되는 이유는 복잡한 데이터들을 모두함께 보지 못해서 입니다. 각 플랫폼에서 수집하는 모든 데이터를에 한곳에 모으고 각 데이터 끼리의 관계를 설정해줘야. 비로서 AI가 모든 데이터들을 이해합니다.
커머스 브랜드가 AI 시대에 진짜로 먼저 해야 할 일은 간단합니다.
데이터를 한 곳에 모으고, 서로 관계를 설정하는 것.
이건 선택이 아니라 필수 인프라입니다. 전기나 수도처럼요. 그리고 이 인프라는 한 번 깔아두면 그 위에서 AI, 자동화, 리포트, 의사결정이 전부 살아납니다.
라플라스는 바로 그 인프라를 제공합니다. 사장님과 마케터가 데이터를 정리하느라 시간을 보내는 게 아니라, 정리된 데이터에서 답을 얻는 데 시간을 쓸 수 있도록.
AI 시대의 경쟁력은 더 좋은 AI를 쓰는 데서 오지 않습니다. AI가 제대로 일할 수 있는 데이터 환경을 먼저 갖춘 브랜드에게서 옵니다.